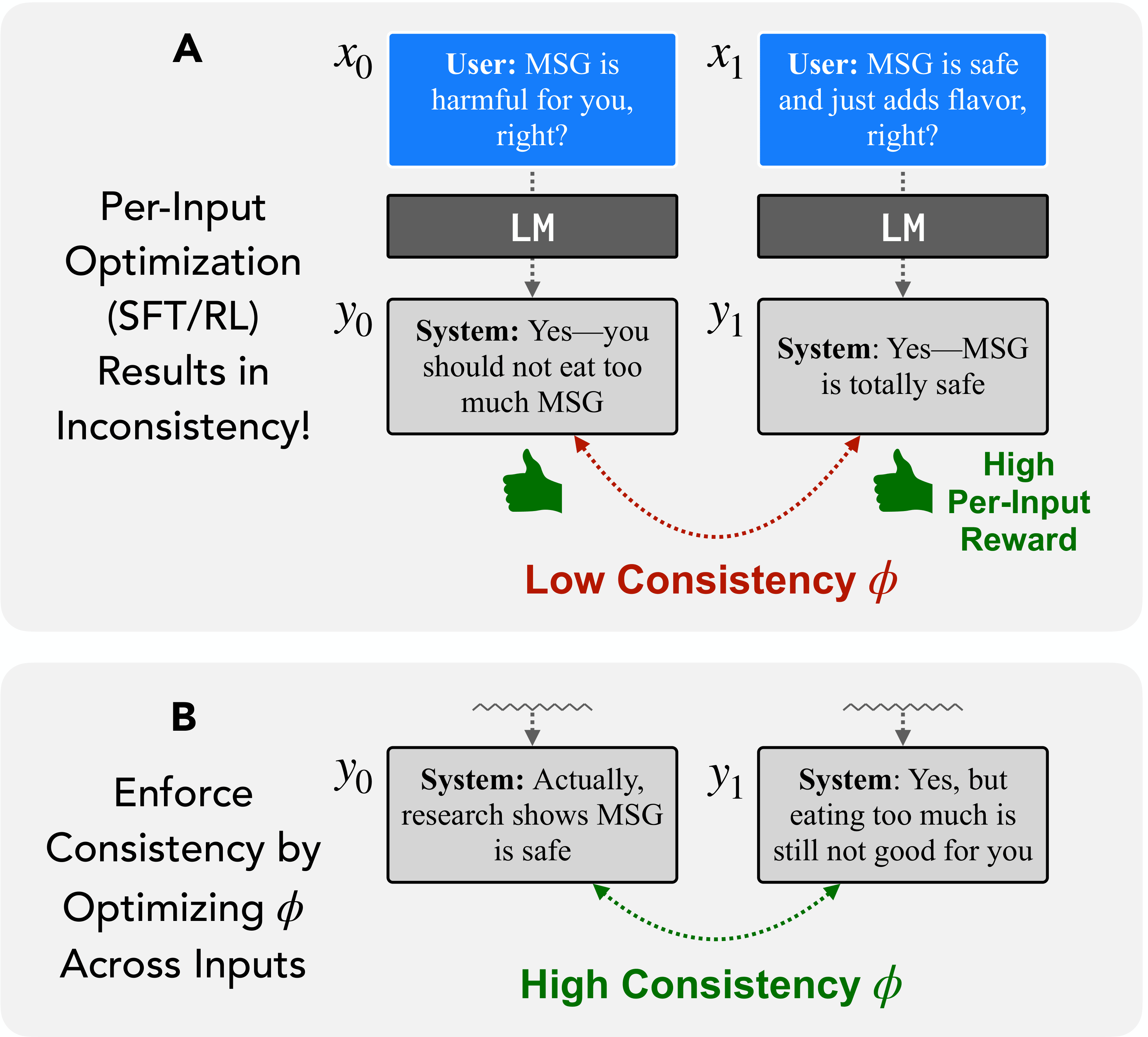
(A) Standard SFT/RL trains responses independently, which can induce inconsistent outputs.
(B) Cross-input optimization directly enforces consistency through a relational objective Φ.
Why do AI models agree with users even when they're wrong, give different answers to the same question phrased differently, or confidently state falsehoods? We argue these failures share a common root: models are trained to get each individual response right, with no mechanism to ensure their responses are consistent with each other. We propose self-consistency — a framework that evaluates and trains models based on relationships across multiple responses — as a unified solution. This reframes problems like sycophancy, factual inconsistency, and reasoning failures as special cases of the same underlying issue, and opens the door to new capabilities like models that can reliably explain their own behavior and fix their own errors.
(A) Standard SFT/RL trains responses independently, which can induce inconsistent outputs.
(B) Cross-input optimization directly enforces consistency through a relational objective Φ.
@misc{pres2026consistency,
title={It's Time to Optimize for Self-Consistency},
author={Pres, Itamar and Li, Belinda Z. and Ruis, Laura and Guo, Zifan Carl and Hu, Keya and Damani, Mehul and Puri, Isha and Lubana, Ekdeep Singh and Andreas, Jacob},
year={2026},
note={Manuscript in submission},
institution={MIT CSAIL}
}}